


 注:2月にこの記事を発表した当初は、初期の思考実験だった。以来、私は大手出版社と「生成AIのデザインパターン」の執筆に取り組み始めている。このスペースで私のパターンやアイデアのアップデートを更新し続けるために、私をフォローしてください。
注:2月にこの記事を発表した当初は、初期の思考実験だった。以来、私は大手出版社と「生成AIのデザインパターン」の執筆に取り組み始めている。このスペースで私のパターンやアイデアのアップデートを更新し続けるために、私をフォローしてください。
AIパターンのニーズ
私たちは皆、新しいものを作るときには、すでに試された手法やアプローチ、パターン等を採用するでしょう。しかし、生成AIや人工知能そのものについては、一概にそうとも言い切れません。生成AIのような新しいテクノロジーでは、私たちのソリューションの土台となる、きちんと文書化されたパターンがありません。
ここでは、数え切れないほどのLLMのプロダクション実装の評価に基づいて、生成AIのためのいくつかのアプローチとパターンを共有します。コストやレイテンシー(遅延時間)、ハルシネーションなど、生成AIの実装に関するいくつかの課題を軽減し、克服するための参考にしていただけたら幸いです。
パターン一覧
- レイヤーキャッシング戦略による微調整
- 専門家パネルのためのAIエージェントの多重化
- 複数のタスクに対するLLMの微調整
- ルールベースとジェネレーティブの融合
- LLMとナレッジグラフの活用
- 生成的AIエージェントの群れ
- モジュラーモノリスLLMアプローチとコンポーザビリティ
- LLMの記憶認知へのアプローチ
- レッドチームとブルーチームのデュアルモデル評価
1)レイヤーキャッシング戦略による微調整

ここでは、大規模な言語モデルにキャッシュ戦略とサービスを導入する際に、コスト、冗長性、学習データなどの要素を組み合わせて解決しています。
これらの初期結果をキャッシュすることで、システムは後続のクエリ(問い合わせ)に対してより迅速に回答を提供し、効率を高めることができます。さらに、十分なデータを得た後の微調整レイヤーでは、初期段階でのやり取りから得られたフィードバックをもとに、より特化したモデルを改良します。
専門化されたモデルは、プロセスを合理化するだけでなく、AIの専門知識を特定のタスクに合わせて調整し、カスタマーサービスやパーソナライズされたコンテンツ作成のような、精度と適応性が重要な環境で非常に効果的なものになります。
GPTCacheのようなビルド済みのサービスや、Redis、Apache Cassandra、Memcachedのような一般的なキャッシング・データベースを使って自分で作ることもできます。サービスを追加する際には、必ずレイテンシーを監視・測定してください。
2)専門家パネルのためのAIエージェントの多重化

特定のタスクに特化した複数の生成AIモデル(「エージェント」)が、それぞれがその領域のスペシャリストであり、クエリに対処するために並行して動作するエコシステムを想像してみて下さい。この多重化戦略により、多様な回答が可能になり、それらが統合されて包括的な回答が提供されるでしょう。
この設定は、問題の異なる側面が異なる専門知識を必要とするような複雑な問題解決シナリオに理想的で、大きな問題の各側面に取り組む専門家チームのようなものだと私は捉えます。
GPT-4のような大きなモデルは、コンテキストを理解し、これを特定のタスクや情報要求に分解し、小さなエージェントに渡します。エージェントは、Phi-2やTinyLlamaのような小さな言語モデルまたは特定の性格、コンテキストプロンプト、関数呼び出しを持つGPTやLlamaのような汎用モデルである可能性があります。
3)複数のタスクに対するLLMの微調整

ここでは、大規模な言語モデルを単一のタスクではなく、複数のタスクで同時に微調整します。これは、異なるドメイン間での知識とスキルの確実な伝達を促進し、モデルの汎用性を高めるアプローチです。
このマルチタスク学習は、バーチャルアシスタントやAIを搭載した研究ツールなど、様々なタスクを高い能力で処理する必要があるプラットフォームにとって特に有用です。これにより、複雑なドメインに対するトレーニングとテストのワークフローを簡素化できる可能性があります。
LLMをトレーニングするためのリソースやパッケージには、DeepSpeedやHugging FaceのTransformerライブラリのトレーニング機能などがあります。
4)ルールベースとジェネレーティブの融合

既存のビジネス・システムや組織のアプリケーションの多くは、いまだにややルール・ベースな部分があります。生成的なものとルールベースのロジックの構造化された正確さを融合させることで、このパターンは創造的でありながらコンプライアンスに準拠したソリューションを生み出すことを目指します。
これは、アウトプットが厳しい基準や規制を遵守しなければならない業界にとって強力な戦略であり、AIが望ましいパラメーターの範囲内にとどまることを保証しながら、革新とエンゲージメントを実現することができます。この良い例は、電話IVRシステムや従来の(非LLMベースの)チャットボットのインテントとメッセージフローを生成することです。

ナレッジグラフ*1を生成AIモデルと統合することで、事実指向のスーパーパワーが得られ、コンテキストを認識するだけでなく、より事実に基づいた正しいアウトプットが可能になります。
*1 ナレッジグラフ:
さまざまな知識(=ナレッジ)を体系的に連結し、グラフ構造で表した知識のネットワーク
このアプローチは、教育コンテンツの作成、医療アドバイス、あるいは誤った情報が重大な結果をもたらす可能性のあるあらゆる分野など、真実性と正確性が譲れないアプリケーションにとって極めて重要です。
ナレッジグラフとグラフオントロジー(グラフの概念集合)は、複雑なトピックや組織的な問題を構造化されたフォーマットに分割し、深いコンテキストを持つ大規模な言語モデルの土台とすることを可能にします。言語モデルを使用して、JSONやRDFなどのフォーマットでオントロジーを生成することもできます。
ナレッジグラフに利用できるサービスには、ArangoDB、Amazon Neptune、Azure Cosmos DB、Neo4jなどのグラフデータベースサービスがあります。また、Google Enterprise Knowledge Graph API、PyKEEN Datasets、Wikidataなど、より広範なナレッジグラフにアクセスするためのデータセットやサービスもあります。
6)生成的AIエージェントの群れ

自然の大群や群れからヒントを得たこのモデルは、多数のAIエージェントが集団で問題に取り組み、それぞれがユニークな視点を提供します。
結果として得られる集合的な出力は、個々のエージェントが達成しうるものを凌駕する、集合知の一形態を反映しています。このパターンは、創造的な解決策の幅を必要とするシナリオや、複雑なデータセットをナビゲートする場合に特に有利です。
例えば、複数の 「専門家 」の視点から研究論文をレビューしたり、不正行為からオファーまで、一度に多くのユースケースについて顧客とのやり取りを評価したりすることができます。このような「エージェント」の集合体を利用し、すべての入力を組み合わせます。大容量のスウォームの場合、エージェントとサービス間のメッセージを処理するために、Apache Kafkaのようなメッセージングサービスの導入を検討することができます。
7)モジュラーモノリス*2 LLMアプローチとコンポーザビリティ

*2 モジュラーモノリス(Modular Monolith):
ソフトウェアアーキテクチャのパターンの一つで、伝統的なモノリシックアーキテクチャの一枚岩的な構造を維持しながらも、コードベースをモジュール化して管理しやすくするアプローチ。
このデザインは、最適なタスク・パフォーマンスのために動的に再構成できるモジュール式AIシステムを特徴とし、適応性を追求しています。これはスイスアーミーナイフのようなもので、必要に応じて各モジュールを選択し、起動させることができるため、さまざまな顧客とのやり取りや製品ニーズに対してオーダーメイドのソリューションを必要とするビジネスにとって非常に効果的です。
各エージェントとそのツールを開発するために、様々な自律エージェントフレームワークとアーキテクチャの使用を展開することができます。フレームワークの例としては、CrewAI、Langchain、Microsoft Autogen、SuperAGIなどがあります。
セールスモジュラーモノリスでは、プロスペクティングに特化したエージェント、予約を処理するエージェント、メッセージの生成に特化したエージェント、データベースの更新に特化したエージェントが考えられます。将来的に、専門のAI企業から特定のサービスが提供されるようになれば、与えられた一連のタスクやドメイン固有の問題に対して、モジュールを外部やサードパーティのサービスと交換することができます。
8)LLMの記憶認知へのアプローチ

このアプローチは、AIに人間のような記憶の要素を導入し、モデルがよりニュアンスのある反応をするために、以前のやり取りを思い出し、それを基に構築することを可能にします。
AIが、専用のパーソナル・アシスタントや適応学習プラットフォームのように、時間をかけてより深い理解を深めていくため、継続的な会話や学習シナリオに特に有用です。記憶認知のアプローチは、重要なイベントやディスカッションを時間の経過とともに要約し、ベクトル・データベースに保存することで発展させることができます。
要約の計算量を低く抑えるために、spaCyのような小規模なNLPライブラリや、かなりの量を扱う場合はBART言語モデルを通して要約を活用することができます。使用されるデータベースはベクトルベースであり、短期記憶をチェックするプロンプト段階での検索は、重要な 「事実 」を見つけるために類似検索を使用します。実用的なソリューションに興味のある方には、MemGPTと呼ばれる同様のパターンに従ったオープンソースのソリューションがあります。
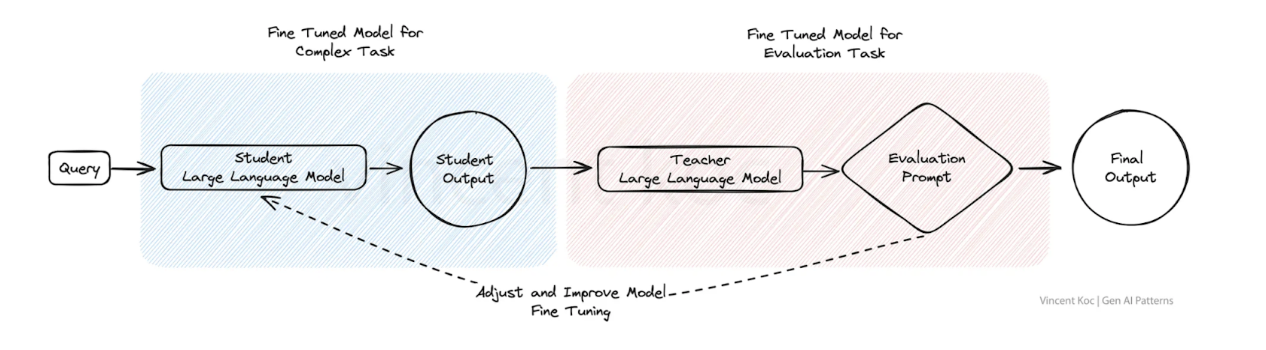
このアプローチは、複雑なタスクに対する人間のフィードバックの一部を、人間のレビュープロセスを模倣するために微調整されたモデルに置き換えるために使用することができ、複雑な言語シナリオやアウトプットを評価するために結果を洗練させることができます。
Takeaways
生成AIのためのこれらのデザインパターンは、単なるテンプレートではなく、明日のインテリジェント・システムが成長するためのフレームワークです。私たちが探求と革新を続ける中で、私たちが選択するアーキテクチャが、機能だけでなく、私たちが創造するAIのアイデンティティそのものを定義することは明らかです。
このリストは決して最終的なものではなく、ジェネレーティブAIのパターンやユースケースが拡大するにつれて、この領域が発展していくのがわかるでしょう。本記事は、Tomasz Tunguzが発表したAIデザイン・パターンにインスパイアされたものです。
この記事をお楽しみいただけましたか?
Vincent Kocは、データドリブンとデジタル分野に特化した豊富な経験を持つ、非常に熟練した、商業的に焦点を当てたテクノロジストであり、フューチャリストである。
Vincent Kocが新しい記事を発表したら、無料でお知らせします。または、LinkedInとXで彼をフォローしてください。
英語版参照元:
https://towardsdatascience.com/generative-ai-design-patterns-a-comprehensive-guide-41425a40d7d0#497f-dc210fc6d47a
DMNでは、他にも様々なブログを「DMN Insight Blog」にて配信しております。
定期的に記事をご覧になられたい方は、ぜひご登録をお願いいたします!
→「DMN Insight Blog」メールマガジン登録
![]()
![]()